
AFFINE Seminar: Weeks 1 - 2
In which I express my confusion

The last 1.5 weeks have been a perfect demonstration of my complete ignorance as to the broader field of AI safety. As I mentioned previously, I’ll use these ~weekly posts as an exposition of my ignorance, or a sort of open notebook. I’ll lead with a little introduction, so if you’re not interested in the gritty details, then just read that! I’m also writing this under a strict time constraint, before quickly proofreading and posting, so don’t expect this to be a complete list of everything I’ve covered in the past ~week or a thorough exploration of my own ignorance on the topics.
Why I am Confused
The fundamental question in superintelligence alignment is how we can deploy an agent many times smarter than ourselves under confidence that the superintelligence, or ASI, will remain compatible with a thriving human civilization.
Abram Demski and Scott Garrabrant’s “Embedded Agency” is probably the best treatment of why some AI researchers think this problem will be very hard. Demski and Garrabrant both work in the field of Agent Foundations, which seeks to build fully verifiable systems of intelligence. Agent foundations often sounds very theoretical, and it is hard to understand why it will necessarily hold for intelligent systems built in reality. The tension between the “philosophical” approach of agent foundations and the “empirical” approach of frontier labs sits at the heart of current AI safety discourse.
In a talk Demski provided at our seminar this week, he shared a breakdown of agent foundations research broken down into four categories: Philosophy, Mathematics, Learning-Theoretic and Computational.1 Each layer is one step closer to “ground truth.” I find this framing pretty elucidating for AI safety research broadly, though I think we could further differentiate these layers between theory and empirical work.
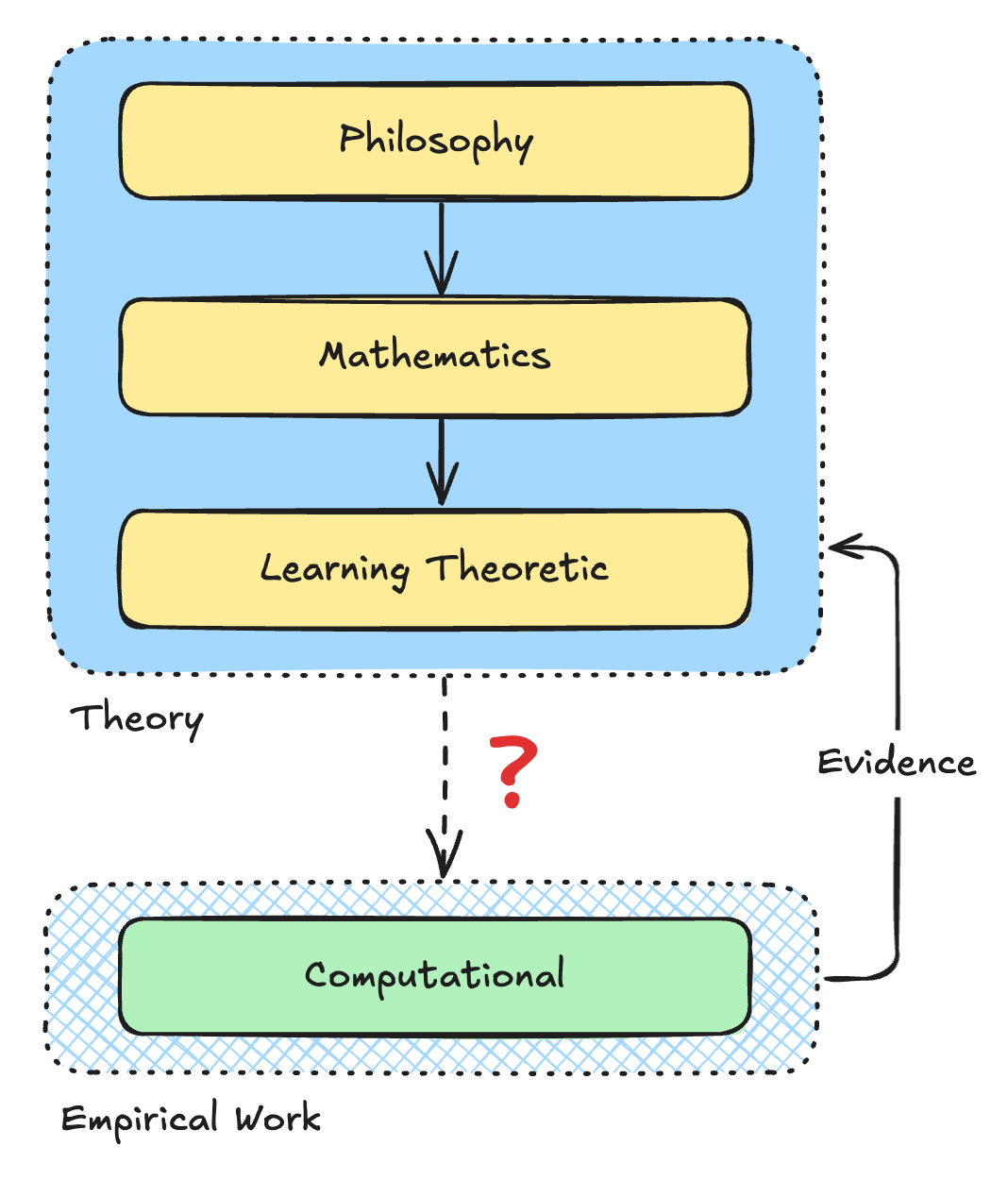
For the duration of the seminar, I’ve decided to focus my research toward the connection between theory and empirical work. I’ve become more open to the idea that some highly “philosophical” research areas like decision theory could have a direct impact on the development of safe AI. But I would like to see more emphasis placed on testable claims, especially when theory asserts dramatic outcomes for superintelligence. I worry some agent foundations work builds on top of contestable claims about the future of artificial intelligence, without rigorously addressing those assumptions.
For example, I am skeptical of claims like Soares’s Sharp Left Turn, which ought to formulate a possible takeoff scenario for superintelligence, rather than a necessary takeoff scenario. Further work clarifying why we do or do not believe such scenarios will occur seems very valuable to me, even if the outcome is indeed to assert our fundamental uncertainty about these risks.
To quote Paul Christiano’s response to Soares’s argument:
More concretely, you talk about novel mechanisms by which AI systems gain capabilities, but I think you haven’t said much concrete about why existing alignment work couldn’t address these mechanisms. This looks to me like a pretty unproductive stance; I suspect you are wrong about the shape of the problem, but if you are right then I think your main realistic path to impact involves saying something more concrete about why you think this.
To this end, I am spending a lot of time learning about mechanistic interpretability, or “mech interp,” and hope to complete a small group research project during the seminar that employs mech interp to explore theoretic implications for current AI. A naive example of this might be ablating components in a neural network to try to explain behavior that deviates from a training objective.
A visiting mech interp researcher differentiated “ambitious mech interp” and “pragmatic mech interp,” with the former directed at the theoretic implications of modern neural network behavior, and the latter directed at more mundane (if still practical) safety procedures like detection. I’m sympathetic to pragmatic mech interp, as it still provides us tools which can contribute to further alignment research. But the distinction points toward a meaningful difference in aligning current vs future intelligence, so I’ve adopted the “ambitious mech interp” label for my current research direction.
Catching up on Neural Networks
A lot of the participants here are earlier in their career than I am, but know far more than I do about neural network (NN) architecture and current algorithms and techniques. Obviously there is a selection bias in the participants at this seminar, but it does seem to highlight for me how much Computer Science education has shifted in this direction since I was at the start of my career.
I’m cognizant that upskilling on all of deep learning / reinforcement learning during the seminar is an unfeasible task, though it does give me a clear study direction for the rest of the year. For now, I’ve been spending a bit of time each week working through the fast.ai deep learning course and going through the introductory ARENA materials on building a transformer from scratch. Knocking my head against the transformer architecture was particularly important, as it’s really difficult to have any conversation about empirical work without a basic understanding of one-hots, attention heads, MLPs, residual streams, etc. I had a basic understand of transformers before attending the seminar, but not at the right level of granularity for in-depth conversation with a researcher.
This is a bit out of scope for now, but I have also been quite interested in understanding the implications of specific NN architectures or training/learning algorithms for AI safety. For example, this paper on machine interruptibility requires a separate policy function to determine behavior, while the behavior of modern LLMs is determined primarily by weights. We’ve also had some interesting discussions this week explaining how modern NNs bias toward “simple” representations of knowledge in the weights, where simplicity correlates with Kolmogorov complexity. However, the K-complexity is also a byproduct of the backpropagation mechanism in modern LLMs, which enables complex, emergent behavior across transformer layers. A purely feedforward network would be more likely to optimize for something like circuit complexity, which would typically require a much larger set of neurons.
Mechanistic Interpretability
Every time I try to dive into mech interp techniques (probes, sparse auto-encoders, transcoders) I get derailed by my basic ignorance of neural network architecture. So I haven’t made much progress learning actual techniques.
However, I’ve read a few good papers on the subject. Goodfire recently published a very interesting paper explaining how they were able to detect and ablate individual components from a language model. We can find examples of ablation in neural networks since at least 2018, but Goodfire is building on top of research from the past several years indicating that NN behavior is often formed across multiple layers/heads, and often involves multiple features superimposed into a single “neuron.” The procedure of actually identifying individual components working across multiple heads/layers is an important research area in mech interp (Anthropic’s new Head Vis is a more discrete example of tooling meant to assist in this work)
Though I haven’t read it yet, Goodfire also published a very flashy paper about the geometric representation of concepts in neural networks.
Math
I have also been spending a lot of time trying to understand the mathematical formalizations within a neural network (particularly in a transformer architecture). I have a solid intuition for the general procedure of matrix manipulation within a neural network, but none of the granular understanding for the exact procedure occurring at each step.
I would like to be able to summarize all mathematical procedures in Anthropic’s “A Mathematical Framework for Transformer Circuits” (2021). Working through each step in the architecture, there are lots of definitions that are relatively easy to understand. But the paper hides a lot of details which come up once you start digging through the background literature. And going from an intuition for a single step in the architecture to the entire procedure is hard.
To keep up with the more advanced formalizations, I’m also having to review some linear algebra, which is giving me a chance to finally work through “Linear Algebra Done Right.”
I’ve also been reading ~1 machine learning paper each day as a forcing function to learn the mathematical formalizations of the field. I’ve been surprised how much I related to Jeremy Howard’s comments that, once you learn the lingo, most ML formulas can be translated pretty directly into programming language. So it tends to feel more like learning a new programming language and new primitives than it does feel like learning new math. Or, that feels true while you are still working with the higher-order abstractions. I am generally lost once I start digging into the details.
For example, reading the layer norm paper took me from this:
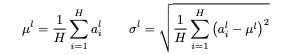
to this:
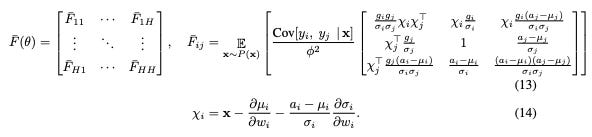
I also learned an incredibly interesting argument connecting the behavior of ideal Solomonoff induction run on a universal Turing machine, down through lower-compute specifications to gradient descent as it’s run for a modern neural network. I believe this theory is only partially written up, so I will refrain from explaining the topic further out of respect to the researcher.
Mathier Math
I’ve also ended up in a study group for category theory and infra-bayesianism. I am not clear why the two are connected.
Infra-bayesianism is a learning theory that extends standard Bayesianism with the concept of partial hypotheses and a new decision-heuristic that weights toward “least bad” or lowest risk policies. This addresses some operational flaws in a standard Bayesian model of decision making, which might presuppose an ability to compute all possible worlds, or fail to account for risk-aversion in calculating expected value (EV). Infra-bayesian addresses this with a more formal qualification of “knightian uncertainty” and its selection of low-risk policies, rather than actions. I think the choice of a policy over an action could entail some interesting applications of Updateless Decision Theory (UDT), but this vis ery much still a new area for me (take the previous explanation with a grain of salt).
Continual Learning and World-Models
A common sentiment in the AI community is that we cannot reach AGI without continual learning and world models, which may require fundamentally new architectures.
I have always been a bit confused by this sentiment. It seems like transformer architectures have been able to scale remarkably well! Why are researchers as varied as Yann LeCun and Jeremy Howard and Steven Byrnes so skeptical of the scalability of LLMs?
I’ve been surprised to see how many fellows at the residency are sympathetic to this sentiment, with justifications ranging from active inference to singular learning theory to consequentialism to embedded agency.
I’ve been reading more about Yann LeCun’s JEPA architecture, to better understand the rationale and some of the formalizations.
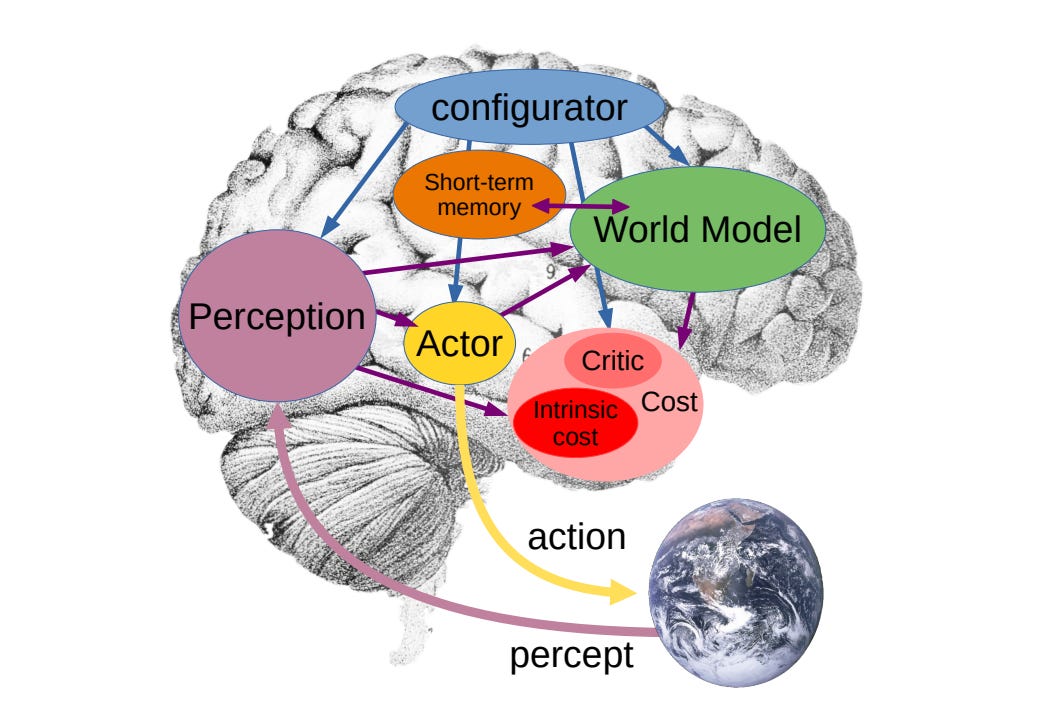
What I’ve read so far about the architecture makes sense to me. What is not yet clear to me is whether this would actually necessitate a fundamental re-design of the typical transformer architecture to handle continual learning and world models, or if this is something one could address by building on top of or alongside current LLM architectures. I am not going to speculate as to what such an architecture might look like, since this would probably be a Bad Thing. But it’s an important reminder of how model architecture may still undergo significant shifts before we reach AGI.
Anthropomorphism and Moral Philosophy
Does ethics have a direct bearing on superintelligence alignment? I’m not sure! The approach taken by Anthropic indicates that it might. But my current best guess is that moral philosophy is not useful for superintelligence alignment, except insofar as we should clarify for ourselves where ethics is (A) anthropomorphic and (B) game theoretic.
As I’ve mentioned repeatedly, I am very skeptical moral realism. It seems that most human ethics is downstream of our biology, or otherwise culturally mediated. It’s possible that some ethical taboos—like murder and theft—provide game theoretic advantages for a species (i.e. if a species has to expend excess energy defending against rampant theft and murder this reduces the remaining energy to survive and reproduce, meaning species with less murder/theft are more likely to thrive). But we also don’t have clear ethical taboos for behavior which might provide game theoretic disadvantages for a species (e.g. immortality, which might reduce population robustness). So it seems like our ethics are very anthropomorphic and perhaps impossible to “rationalize” to an alien intelligence.
This seems to lead into a broader problem where even theoretic research on artificial intelligence seems to fall into latent assumptions about what intelligence and agenthood might look like. Consider for example our conception of the diachronic self, which asserts the self is a single, coherent identity persisting across time. This is quite clearly an illusion! The self is incredibly transitory. Our beliefs and underlying neurophysiology are subject to tremendous changes over time. But we do have a strong biologically or culturally mediated belief that we maintain a consistent self across time. And even if the “self” is temporal, we do seem to have a single unified experience of those selves.
It is unclear if any of this would hold for a future ASI. An LLM only “thinks” when it is activated. Would an ASI have a strong desire to ensure it’s always active, the way we strive to stay alive? Would it want to maintain a diachronic self, and so avoid creating a more intelligent successor ASI? Maybe not! It’s possible an ASI would behave and rationalize across activations and successor models, completely indifferent to persistence of a “diachronic self.” It’s possible it could also have a perfect understanding of human morality through its training set, and find no convincing dictum to modify its behavior.
We should acknowledge that the radically alien behavior of an ASI could make it impossible to guide with ethics.
Goooooal
One of the more applicable problems in agent foundations is the difficulty of specifying goals and ensuring agent behavior adheres to the explicit and implicit behavior dictated by that goal. In agent foundations this is often understood as inner vs outer alignment or “mesa-optimization” and Goodhart’s law.
The core principle here is that it is very hard to specify even simple goals unambiguously (e.g. monkey’s paw problem), and that even once a goal is specified an agent might actually optimize for a proxy of that goal. Often this relates to problems of out-of-domain generalization, or OOD. Consider this well-known example about an agent trained to find the exit from a maze. The exit happened to be green. Later, the researchers made the exit red and placed a green apple at the center of the maze. The agent then pursued the green apple rather than the red exit. More examples to this effect can be found in this paper from Deep Mind.
How could one fully specify the whole of human ethics, for example? Is this even coherent? What would it mean to align an AI to all society—do we simply take the average of all human preferences? Do we take the average coherent extrapolated volition (CEV)? Or the average CEV assuming a finite level of superior intelligence? Could any of these things even be meaningfully defined? And even if we do manage to define this goal, how could we verify actual model behavior follows from it?
I am somewhat critical of the outer/inner alignment problem as another example of anthropomorphism. As far as I see it, there is no “outer goal.” Rather, the AI researchers responsible for training an AI have a goal (to create aligned AI), which may or may not be latent in the trained weights and model architecture. It’s incorrect to say the trained intelligence is “misaligned” with its outer goal. Rather, we have developed an agent with a goal which imperfects represents our training objectives. This is a somewhat pedantic difference, but helps prevent us from anthropomorphizing the agent as somehow “cheating” on its outer goal by creating a proxy.
Yudkowsky likes to use our deviation from evolutionary objectives of reproduction as an example of outer/inner misalignment. I think this perfectly represents the confusion, as there is no actual goal to evolution. Evolutionary fitness is an emergent property of multiple competing forces. Our human goals are not a misaligned “proxy” of an evolutionary goal to reproduce. They are simply the emergent goals rising from evolution’s “training set.”

This is similar to but better than the list I provided last week, which used “Foundations” in a non-idiomatic way